
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- ionehotencoding
- scikit-learn
- SQL
- iNT
- pyspark
- Word Cloud
- Python
- 형태소분석기
- Okt
- Tableau
- pandas
- 파이썬
- 인공지능
- 크롤링
- 데이터
- 태블로
- selenium
- numpy
- konlpy
- 시각화
- 데이터분석
- 데이터 분석
- input
- Udemy
- 머신러닝
Archives
- Today
- Total
반전공자
[PySpark] 액션 - count(), saveAsTextFile(), foreach() 본문
토마스 드라마브, 데니 리의 "PySpark 배우기"를 보고 배워나가는 과정을 기록한 글입니다 ♪
.count(... ) 함수
- 앨리먼트 개수 세기
>>> data_reduce = sc.parallelize([1, 2, .5, .1, 5, .2], 3)>>> data_reduce.count()
6→ 위 앨리먼트 개수 6으로 알맞게 출력
.saveAsTextFile(...) 함수
- RDD를 텍스트 파일로 저장
- 각 파티션을 분리된 파일에!
>>> data_key = sc.parallelize(
... [('a', 4), ('b', 3), ('c', 2), ('a', 8), ('d', 2), ('b', 1), ('d', 3)], 4)>>> data_key.saveAsTextFile('/Users/hayeon/Downloads/data_key.txt')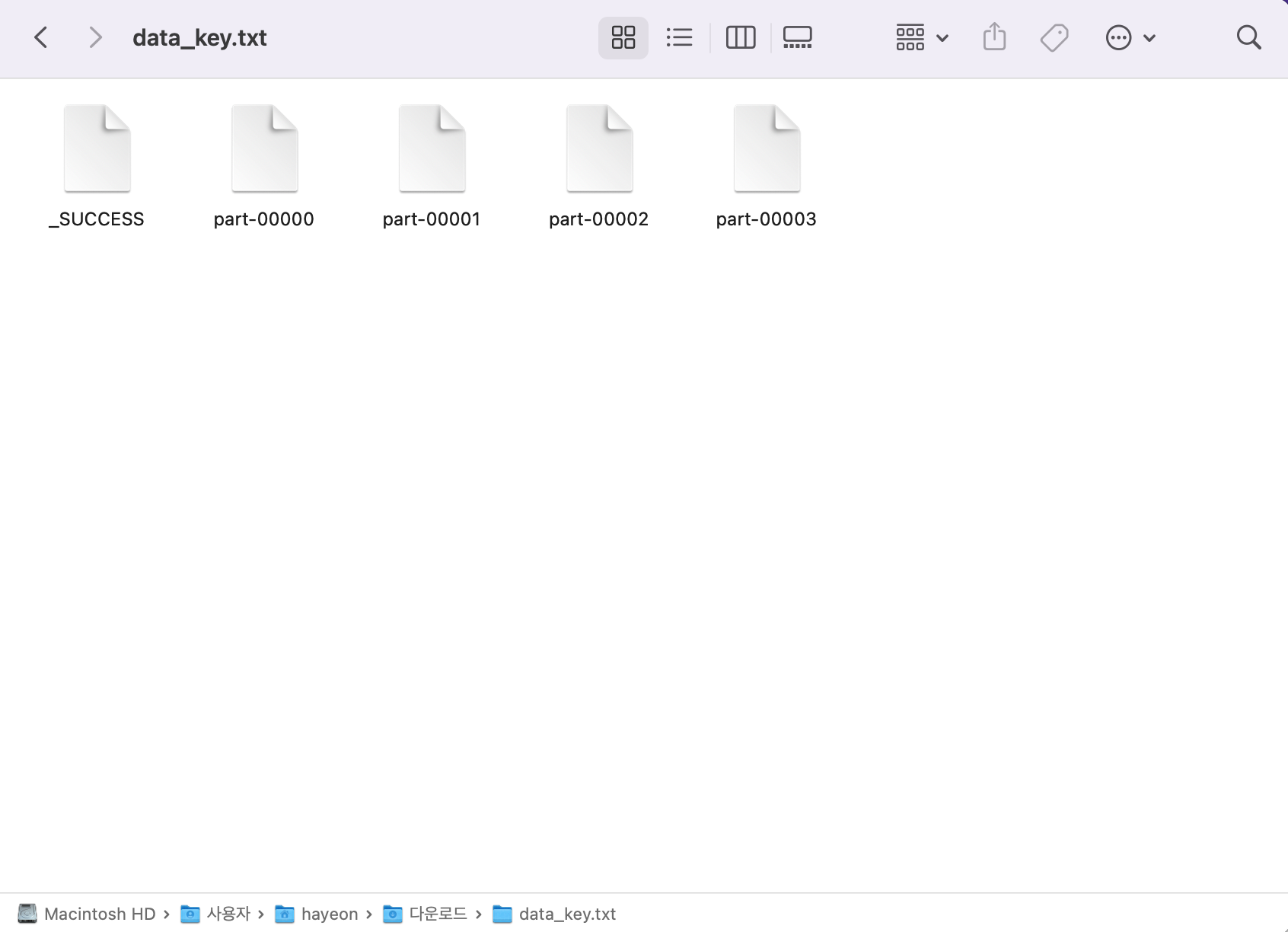
* _SUCCESS : 내용은 하나도 없고 성공적으로 저장했음을 알려주는 파일
* part-00000 : data_key의 첫 번째 파티션 값인 ('a', 4)
* part-00001 : data_key의 두 번째 파티션 값인 ('b', 3), ('c', 2)
* part-00002 : data_key의 세 번째 파티션 값인 ('a', 8), ('d', 2)
* part-00003 : data_key의 네 번째 파티션 값인 ('b', 1), ('d', 3)
- 모든 행이 스트링으로 표시되므로 뒤쪽부터 읽고 싶다면 뒤쪽으로 파싱해야 함
>>> def parseInput(row):
... import re
... pattern = re.compile(r'\(\'([a-z])\', ([0-9])\)')
... row_split = pattern.split(row)
... return (row_split[1], int(row_split[2]))>>> data_key_reread = sc.textFile('/Users/hayeon/Downloads/data_key.txt').map(parseInput)
>>> data_key_reread.collect()
[('a', 8), ('d', 2), ('b', 1), ('d', 3), ('b', 3), ('c', 2), ('a', 4)]
.foreach(...) 함수
- 같은 함수를 RDD의 각 엘리먼트에 반복적으로 적용
- .map() 함수와 달리 정의된 함수를 하나하나 각 데이터에 적용
- PySpark에서 지원하지 않는 DB에 데이터를 저장하고 싶을 떄 유용
ex) data_key RDD에 저장되어있는 모든 데이터 출력
>>> def f(x):
... print(x)→ 단순 데이터 출력 함수를 만든다
>>> data_key.foreach(f)
('a', 8)
('d', 2)
('b', 3)
('c', 2)
('b', 1)
('d', 3)
('a', 4)→ 엘리먼트 하나하나에 모두 함수 f를 적용한 결과, 한줄씩 출력됨을 확인할 수 있다!
'데이터분석 > PySpark' 카테고리의 다른 글
| [PySpark] 데이터프레임 시나리오 : 비행 기록 성능 (0) | 2023.03.11 |
|---|---|
| [PySpark] 데이터프레임 - API, SQL (0) | 2023.03.10 |
| [PySpark] 액션 - take(), collect(), reduce() (0) | 2023.03.10 |
| [PySpark] 트랜스포메이션 - sample(), leftOuterJoin(), repartition() (0) | 2023.03.10 |
| [PySpark] 트랜스포메이션 - map(), filter(), flatMap(), distinct() (0) | 2023.03.10 |
'데이터분석/PySpark' Related Articles
more



