
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Udemy
- iNT
- 데이터 분석
- input
- 파이썬
- Word Cloud
- Tableau
- Python
- selenium
- ionehotencoding
- pandas
- 데이터
- scikit-learn
- 시각화
- 인공지능
- konlpy
- 크롤링
- 형태소분석기
- 태블로
- numpy
- Okt
- pyspark
- 머신러닝
- 데이터분석
- SQL
- Today
- Total
반전공자
R # 그래프 그리기 (막대 그래프) 본문
" 쉽게 배우는 R 데이터 분석 " 을 교재로 하는 글입니다.
저번 산점도에 이어서 막대 그래프를 어느 경우에 사용하는 것이 적합한지, 그리는 방법은 무엇인지 배워보도록 하겠다!
# 평균 막대 그래프
" ex. 성별, 소득 차이 / 집단 간 차이 표현 "
- geom_col()
우리가 자주 본 그래프가 막대 그래프이듯, 실제 분석에도 가장 많이 사용된다고 한다.
그리는 과정을 mpg 데이터를 사용하여 실습해보도록 하자.
< 구동 방식 별 평균 고속도로 연비 >
전처리 패키지 불러온 후 mpg 데이터를 새로운 프레임 안에 넣고, 구동방식으로 그룹핑하고 각 평균 고속도로연비를 구하자.
library(dplyr)
df_mpg <- mpg %>%
group_by(drv) %>%
summarise(mean_hwy = mean(hwy))
df_mpg
# A tibble: 3 x 2
drv mean_hwy
* <chr> <dbl>
1 4 19.2
2 f 28.2
3 r 21 각 구동방식 별로 고속도로 연비의 평균을 보여준다.
이 평균 수치를 가지고 막대 그래프를 그려보자.
ggplot(data = df_mpg, aes(x=drv, y=mean_hwy)) + geom_col()y 축의 데이터를 원래 hwy로 썼지만, 평균으로 그래프를 그려야하기 떄문에 mean_hwy로 바꿔준다.

셋 중 산점도를 그렸을 때의 결과와 같이 f 구동방식의 고속도로 평균 연비가 가장 높은 것을 알 수 있는데,
시각적으로 편리하도록 높은 막대순서대로 정렬해보자.
여기서 포인트 !
# reorder(x축 변수, 정렬기준 변수)
함수만 봤을 때에는 와닿지 않기 때문에 코드를 먼저 볼까?
ggplot(data = df_mpg, aes(x = reorder(drv, -mean_hwy), y = mean_hwy)) + geom_col()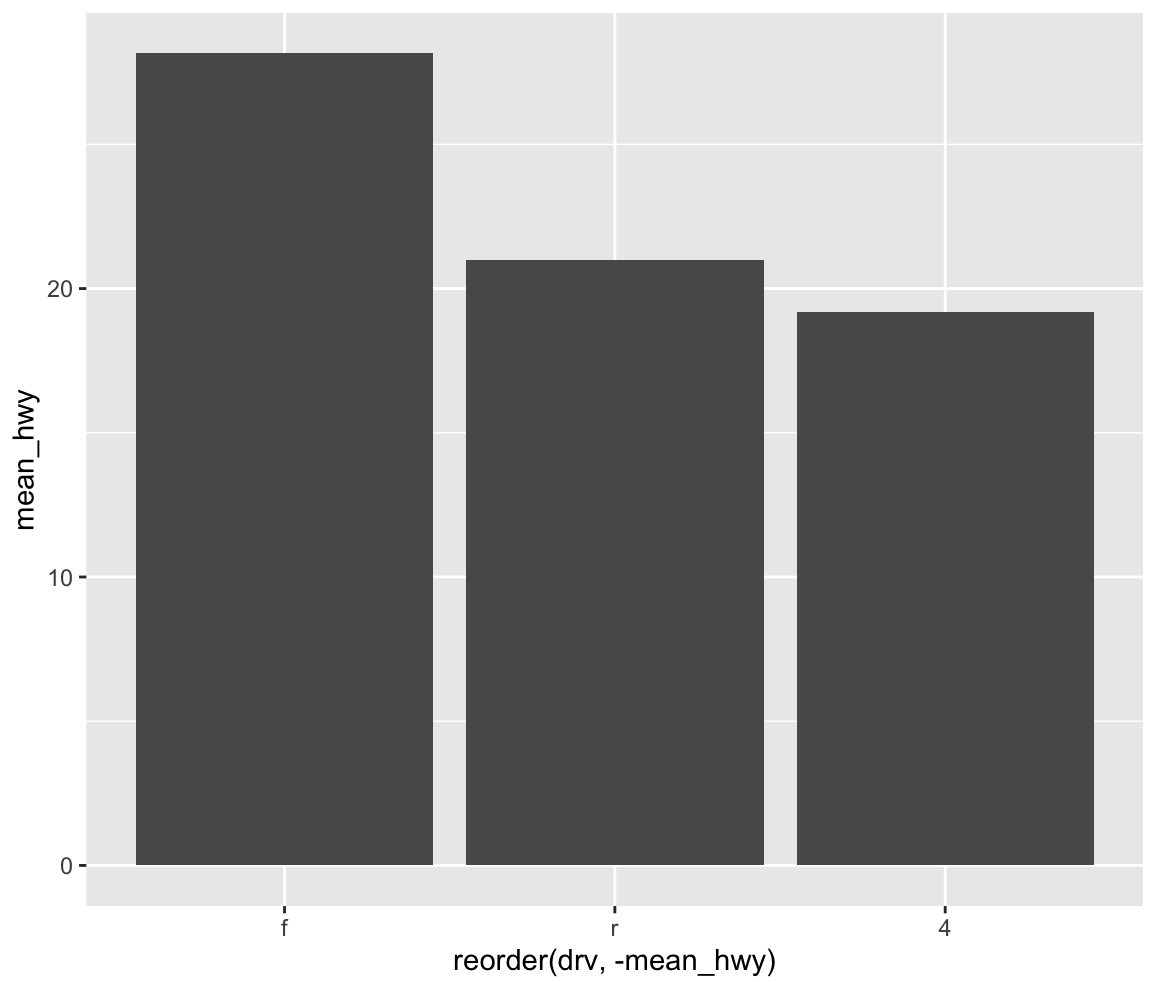
평균 고속도로 연비가 높은 순서대로 정렬이 되었다.
# 빈도 막대 그래프
" 값의 개수로 길이를 표현 "
** x 축만 지정. geom_bar()
ggplot(data = mpg, aes(x = drv)) + geom_bar()각 구동방식 별로 몇 대의 차량이 있는지 빈도를 나타내는 그래프를 그리자.
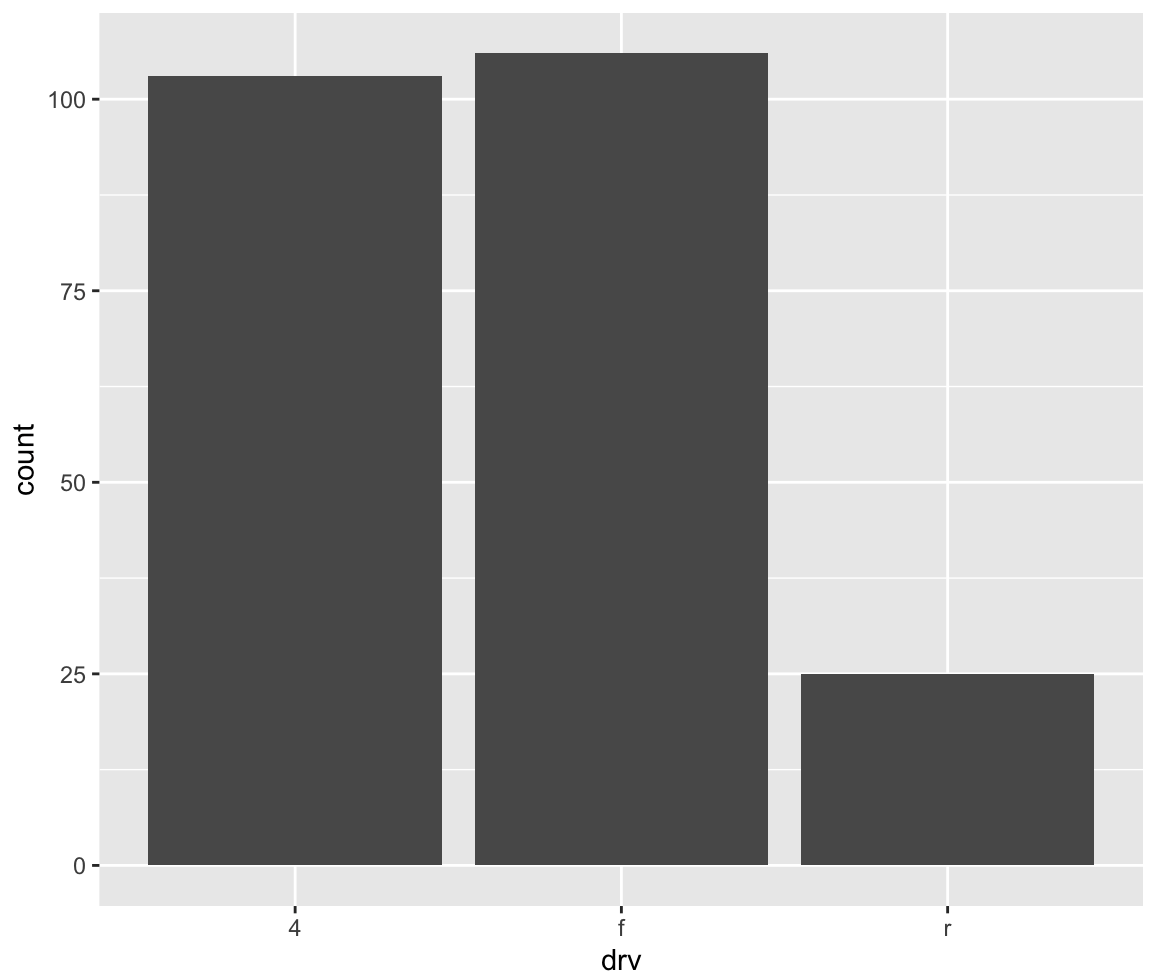
그렇다면 고속도로연비를 가지고 빈도 막대 그래프를 그려볼까 ?
ggplot(data = mpg, aes(x=hwy)) + geom_bar()
위에서 우리는 그래프 그리는 함수를 geom_col(), geom_bar() 두가지를 사용했는데, 둘의 차이가 무엇인가?
geom_col()
- 데이터 요약본
geom_bar()
- 원자료
# 혼자서 해보기, 복습하기
mpg 데이터를 사용하여 실습
1. 어떤 회사에서 생산한 suv 차종의 도시연비가 높은지 알아보자. (suv 차종 대상으로 평균 도시연비 가장 높은 다섯 곳 막대 그래프로 표현, 연비 높은 순 정렬)
mpg <- as.data.frame(ggplot2::mpg)df <- mpg %>%
filter(class=="suv") %>%
group_by(manufacturer) %>%
summarise(mean_cty = mean(cty)) %>%
arrange(desc(mean_cty)) %>%
head(5)class 에서 suv 행 만 뽑아내고,
제조사 별로 그룹핑한다.
그 후 도시연비의 평균을 계산하고,
수가 큰 순서대로 정렬한다.
큰 순서 별로 1위에서 5위까지 뽑아준다.
ggplot(data = mpg, aes(x = reorder(manufacturer, -mean_cty),
y = mean_cty)) + geom_col()
subaru 사의 차량의 도시연비 평균이 가장 높은 듯 하다!
2. 차량 중 어떤 class가 많은지 알아보자. 차량 종류 별 빈도 표현 막대그래프
ggplot(data = mpg, aes(x = class)) + geom_bar()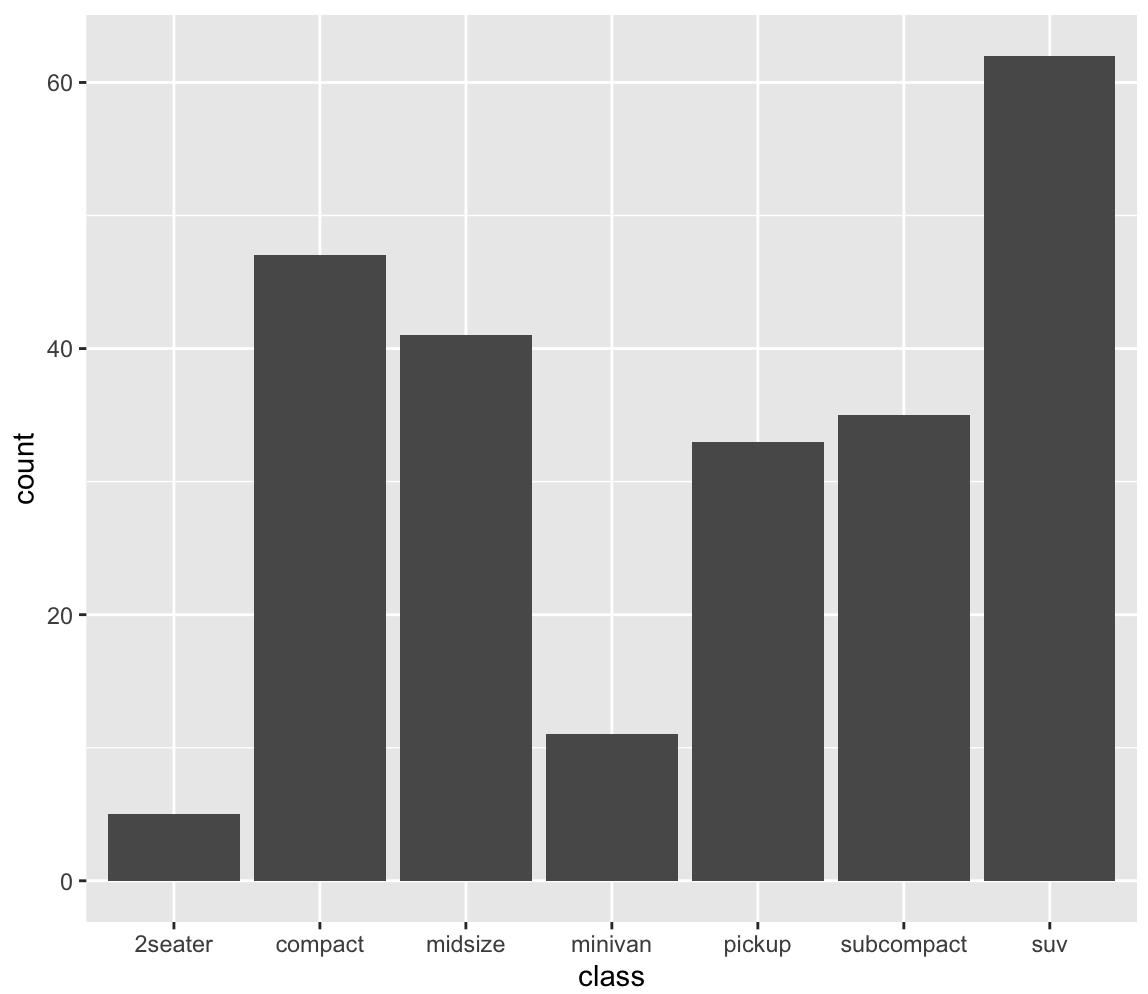
차량의 종류는 suv 종의 차량이 가장 많다.
가장 적은 종류는 2seater 이다.
Q. 빈도 막대 그래프는 원자료만 사용해야하는걸까?
산점도보다는 뭔가 더 혼자 해보는 과제가 복잡하다고 느껴졌지만,
다른 것에 비해 복잡할 뿐 코드 몇 줄이 더 늘어났을 뿐인 것 같다.
더 자유자재로 다룰 수 있도록 꾸준한 연습이 필요할 것 같다 !
'데이터분석 > R' 카테고리의 다른 글
| R # 선 그래프 ( 상자 그림 ) (0) | 2021.02.25 |
|---|---|
| R # 그래프 그리기 ( 선그래프 ) (0) | 2021.02.25 |
| R # 그래프 그리기 (산점도) (0) | 2021.02.24 |
| R # 데이터 정제 (2) (0) | 2021.02.23 |
| R # 데이터 정제 (1) (0) | 2021.02.19 |