
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Word Cloud
- 파이썬
- Udemy
- iNT
- Tableau
- scikit-learn
- pandas
- numpy
- 데이터분석
- selenium
- 형태소분석기
- pyspark
- SQL
- input
- konlpy
- 인공지능
- 시각화
- 데이터 분석
- 머신러닝
- Python
- 태블로
- Okt
- 크롤링
- ionehotencoding
- 데이터
- Today
- Total
반전공자
[Pandas] DataFrame 조회 본문
df4 = DataFrame({'Class': ['IoT','Network', 'Economy','Big Data', 'Cloud'],
'Year': [2018, 2017, 2018, 2018, 2019],
'Price': [100, 125, 132, 312, 250],
'Location': ['Korea','Korea', 'Korea', 'US','Korea']},
index=['C01','C02','C03', 'C04', 'C05'])
원하는 컬럼만 조회
데이터프레임 열 추출, 조회
df4['Class']
* 하나의 컬럼만 선택했기 때문에 시리즈 형식으로 나온다
→ 보기 쉽게, 데이터프레임 형식으로 어떻게 보일 수 있을까?
df4[['Class']]

# Class와 Price 조회
df4[['Class', 'Price']]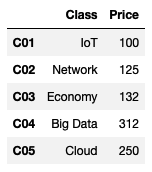
원하는 로우만 조회
데이터프레임 행 조회, 추출
df4.filter(['C01','C03'], axis=0) 
굳이 필터를 쓰지 않고 조회할 방법은 없을까?
loc
: 행의 인덱스(이름)으로 찾아달라
df4.loc['C03']
여기서도 하나의 행만을 선택했기 때문에 시리즈가 나온다.
이때 리스트 안에 넣어서 전달해주면 데이터프레임 형식으로 데이터가 나올 것이다.
df4.loc[['C03']]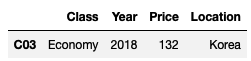
iloc
: 행의 순서를 지정해 찾을 때 사용
df4.iloc[3]세번째 행을 찾아라.
인덱스 슬라이싱
df4['C02':'C04']
→ 원래 인덱스 기호 안에 있는 것은 컬럼문자를 찾는것이다. 그런데 위의 경우는 행 이름을 입력했음에도 불구하고 작동한다. 왜일까?
슬라이싱의 경우, loc, iloc가 생략가능하다.
기본적으로, 컬럼을 먼저 찾지만 컬럼인덱스는 순서가 없다. 때문에 슬라이싱도 물론 불가능하다.
이미 인덱싱은 컬럼에 적용이 불가능하기 때문에 자동으로 행에 가서 작용한다.
∴ loc, iloc를 쓰지 않아도 알아서 행의 이름인 줄 알아듣고 찾아온다.
# 2번째부터 5번째 데이터 선택
df4[1:4]
→ 여기에서는 iloc가 생략된 것이다.
why?
컬럼에는 순서가 없기 때문에 이미 인덱스 슬라이싱이 불가하기 때문.
# 여러 컬럼 선택
df4[['Class','Year','Price']]
그럼 여기서 슬라이싱이 가능할까?
df4['Class':'Price']
loc가 생략된 것이다. 행에서 Class, Price를 찾으라는 의미이다.
왜 행이냐?
→ 반복해 말하지만, 컬럼은 슬라이싱이 불가능하기 때문에 자동적으로 행에서 이름을 찾는다.
행에는 Class, Price가 없기 때문에 아무 결과도 나오지 않는다.
찾기 위해서는 이전 방법으로 추출해야 한다.
원하는 행과 열을 선택하여 조회
# C02, C03 강의의 Class, Year 조회
df4.loc[['C02','C03'].filter(['Class','Year'])
** loc를 사용하면 컬럼도 슬라이싱이 가능해진다.
df4['C02':'C03', 'Class':'Year']
조건색인
# 가격이 200 이상인 데이터만 선택조회
df4[df4.Price >= 200]
한국데이터산업진흥원에서 진행하는 " 데이터 청년 캠퍼스 " 에서 판다스의 기초부터 차근차근 배워가고 있어, 그 과정을 기록한다.
지금까지 시리즈와 데이터프레임을 생성하고 그에 적용가능한 속성, 함수들을 살펴보았는데
이전에 헷갈리거나 어중간하게 알던 것을 더 명확히 할 수 있어 좋다.
매번 모르면 구글링을 통해 해결했는데 이번에 배우면 더 능숙하게 활용할 수 있을 것 같아서 기대된다.
매일매일 7시간동안 강의를 듣지만, 별로 힘들다는 생각은 안들고 시간이 많음에 따라 습득해야하는 지식의 양이 많아서 부지런하게 복습해야 할 것 같다!
'데청캠 연세대' 카테고리의 다른 글
| [데청캠 2022] (0) | 2022.05.10 |
|---|---|
| [Pandas] DataFrame_method (0) | 2021.07.04 |
| [Pandas] DataFrame_attribute(속성) (0) | 2021.07.04 |
| [Pandas] DataFrame (0) | 2021.07.04 |
| [Pandas] Series 실습 (0) | 2021.07.04 |



